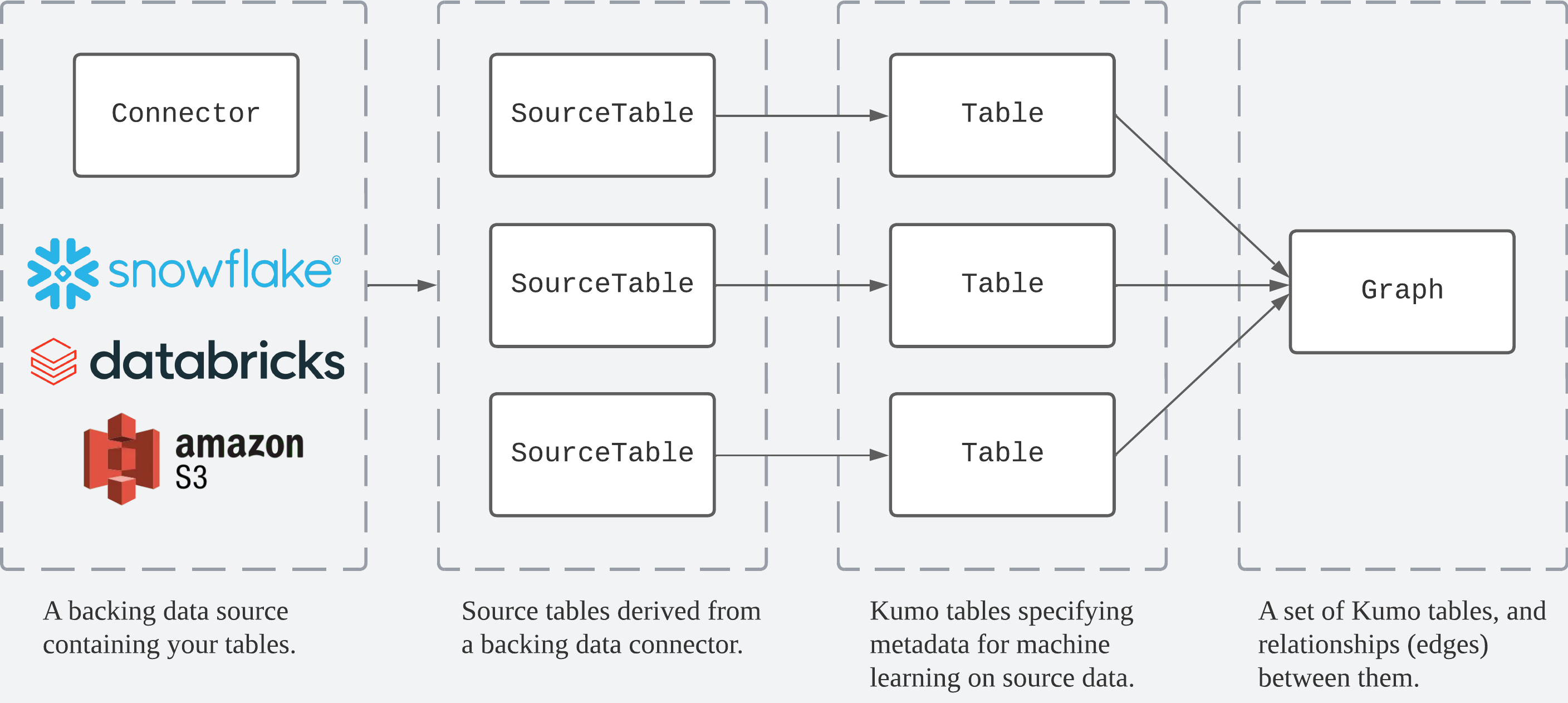
kumoai.connector#
The Kumo Connector and SourceTable interfaces allow users to access and
inspect raw data behind backing connectors. These data can be used to create
Table and Graph objects, which
are for machine learning downstream.
Uploading Your Own Data#
Kumo supports uploading your own tables. Files >1GB are supported by default through automatic partitioning.
Tables must be single Parquet or CSV file on your local machine. Tables can
be uploaded with upload() and deleted
with delete(). They can be used with
FileUploadConnector.
Connector#
Connectors support connecting Kumo with data in a backing data store. The Kumo SDK currently supports the Amazon S3 object store, the BigQuery data warehouse, the Snowflake data warehouse, and the Databricks data warehouse as stores for source tables.
Defines a connector to a table stored as a file (or partitioned set of files) on the Amazon S3 object store. |
|
Establishes a connection to a Snowflake database. |
|
Establishes a connection to a Databricks database. |
|
Establishes a connection to a BigQuery database. |
|
Defines a connector to files directly uploaded to Kumo, either as 'parquet' or 'csv' (non-partitioned) data. |
Source Data#
Tables accessed from connectors are represented as
SourceTable objects,
with source columns represented as
SourceColumn objects.
A source table is a reference to a table stored behind a backing |
|
A representation of an on-going |
|
A representation of an on-going |
|
The metadata of a column in a source table. |